MLNX VMA (消息加速) 模块
MLNX VMA (消息加速) 模块
晨茗一、安装
1 | # Download |
二、测试
通过环境变量LD_PRELOAD即可实现对内核协议栈的替换。
1. Ping-pong
1 | # server side |
内核协议栈
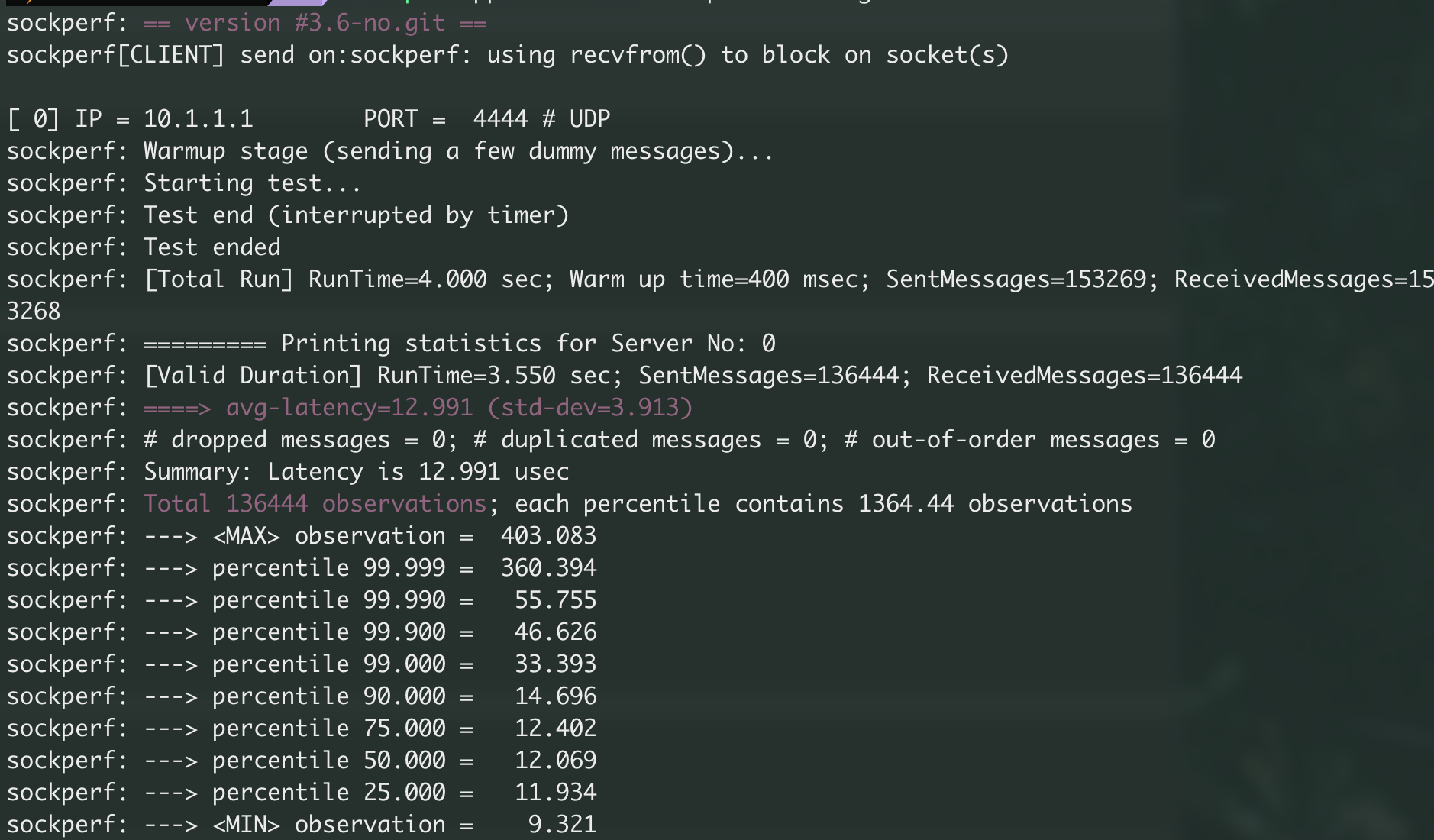
VMA
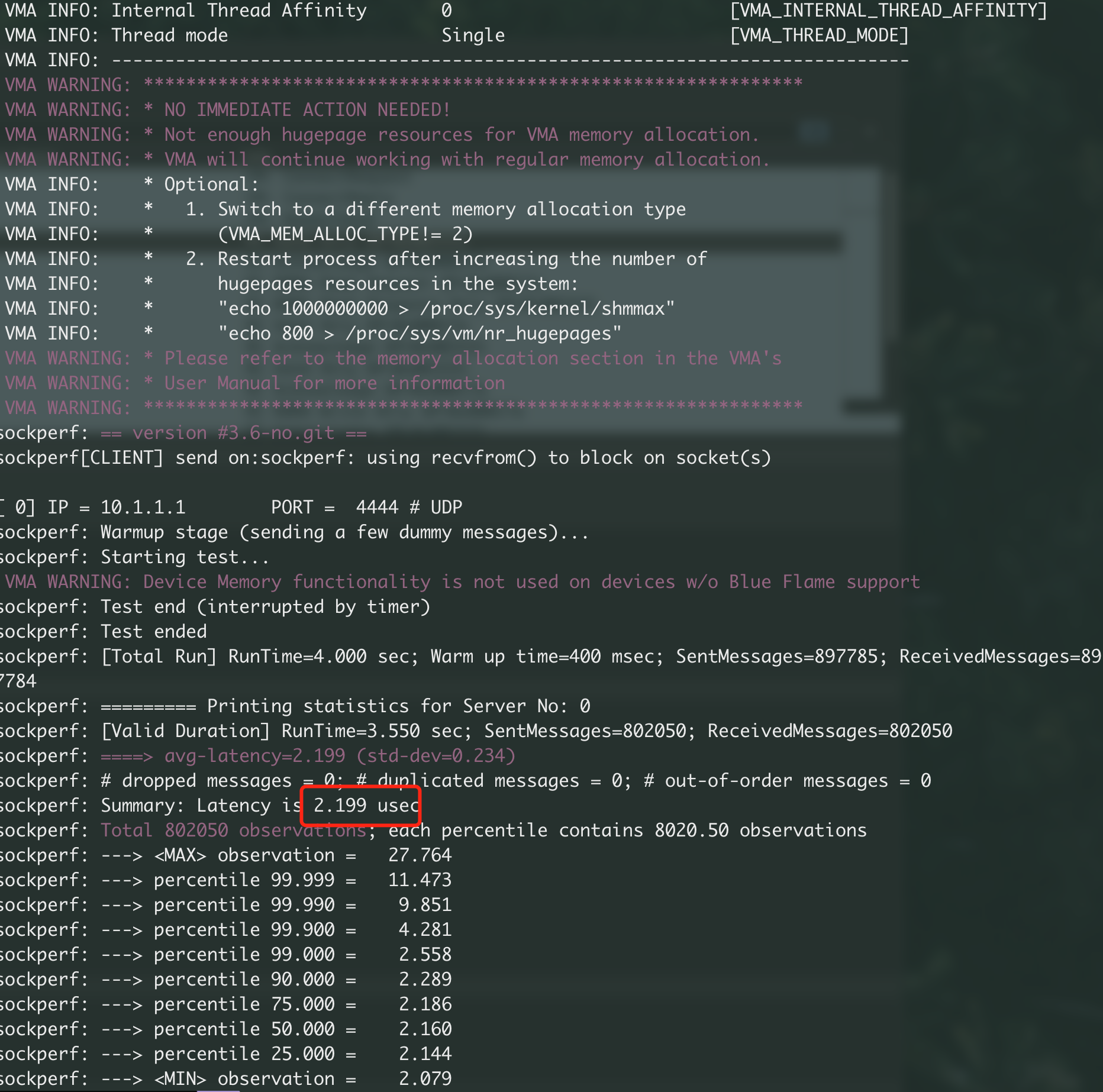
三、结果
通过抓包可以发现 VMA 传输过程中并未对数据包进行修改,只是在两端收发的位置利用 RDMA Verbs 绕过了协议栈,并实现了零拷贝。
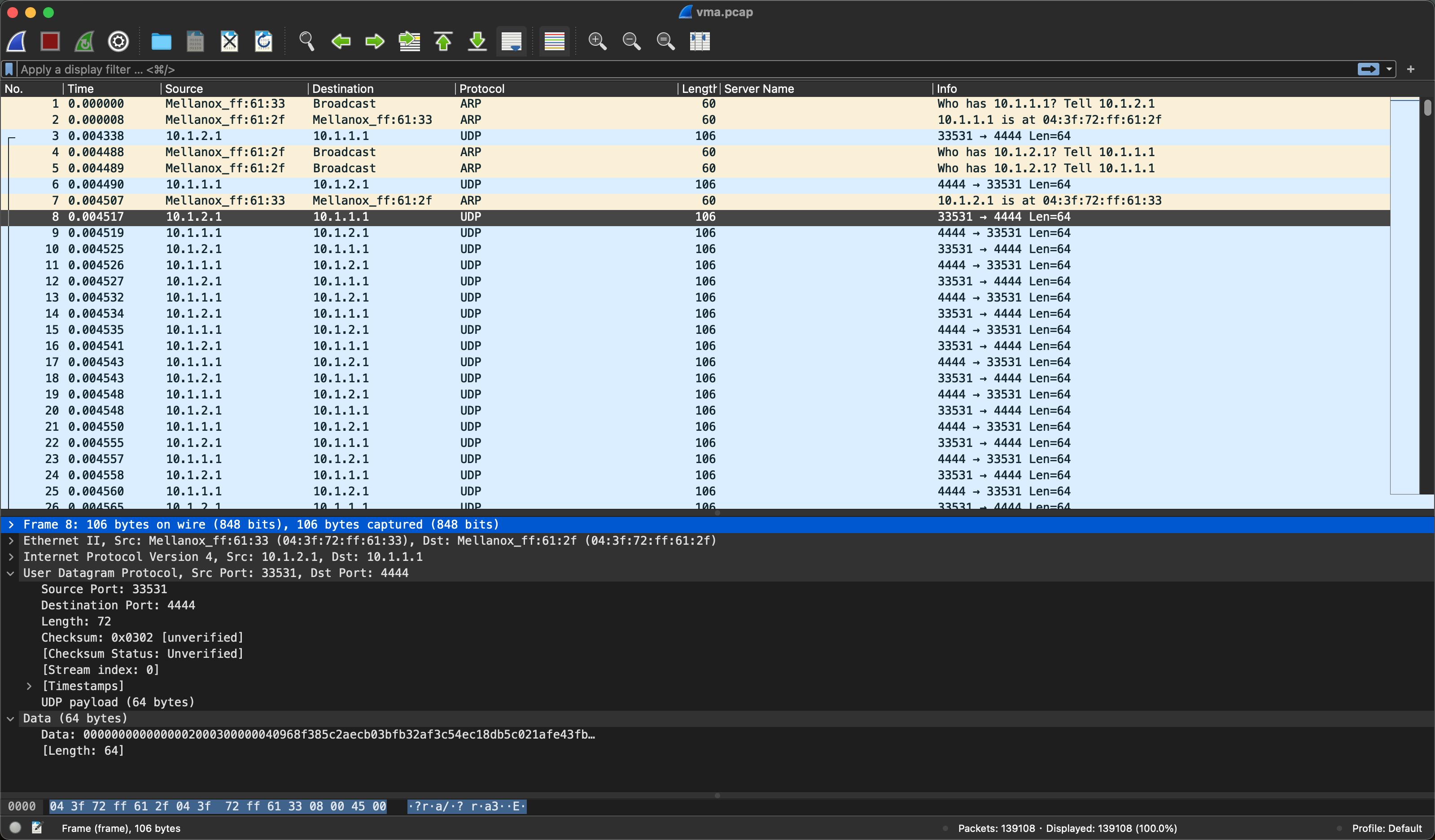
对比下图中的RoCE数据包
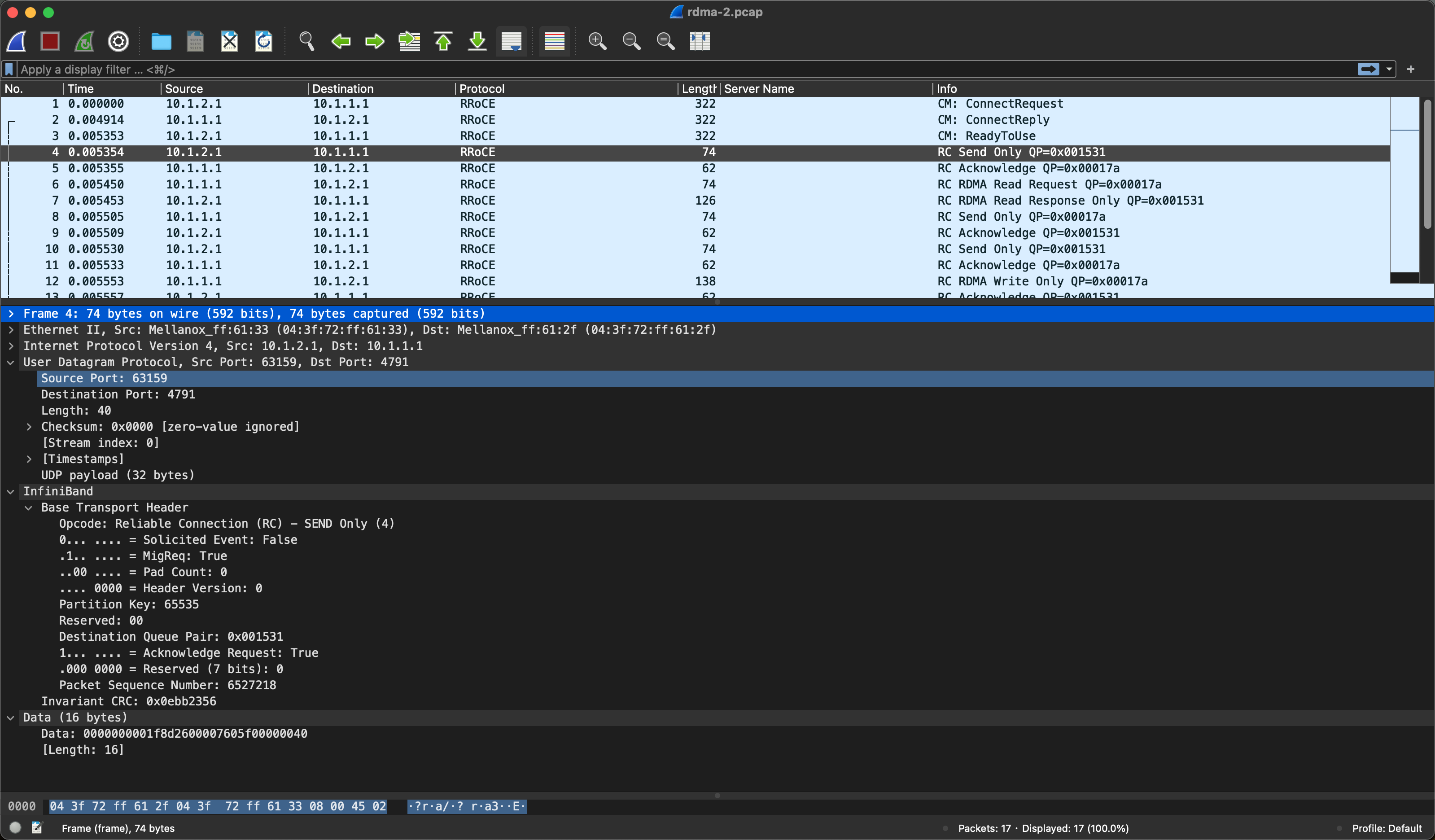
推断其是通过将 QP 设为 IBV_QPT_RAW_PACKET或IBV_QPT_RAW_ETH来进行的收发,通过观察源代码发现其具体代码逻辑和 RDMA 编程非常相似,都是基于工作队列(SQ, RQ)和完成队列(CQ)来实现的,也发现了其 QP 使用的方式是符合推测的。
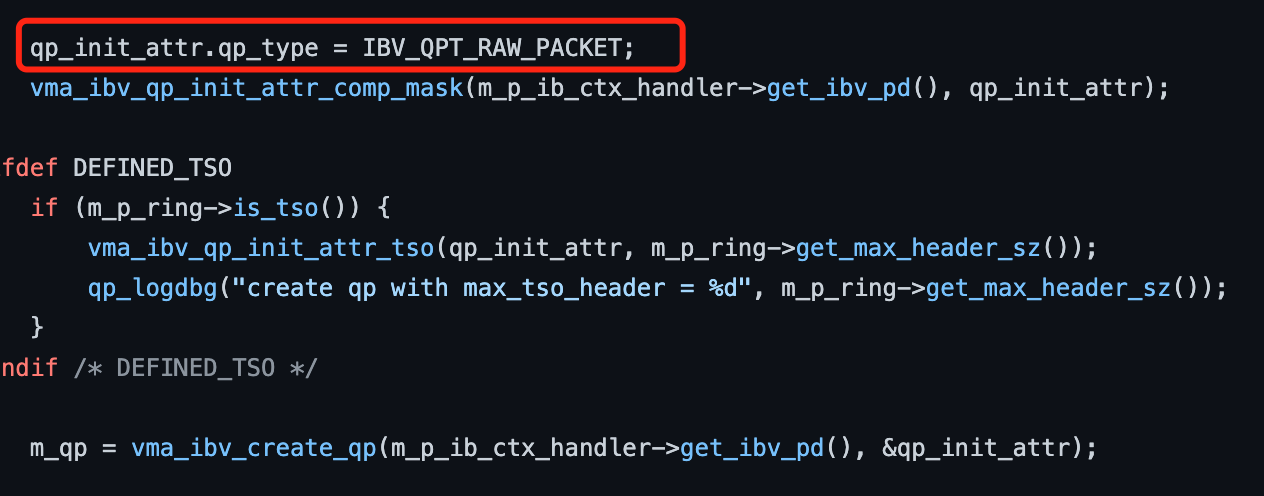
因此可以得出结论的是,VMA 是一个利用了 RDMA Verbs 来实现的 socket 协议栈,它具有了 RDMA 零拷贝和 bypass 的特性,但其使用方式仍是传统的消息模式,与 RDMA 类似内存访问的机制存在本质区别,因此不能实现 offload 特性,对于数据量大的数据,其仍需要两端 CPU 参与消息的收发,而 RDMA 可以只利用客户端的 CPU 完成数据传输。


%20%E6%9C%8D%E5%8A%A1.jpeg)


